Часть 1Часть 2Часть 4Алгоритм поиска эйлерова пути
Посмотрим еще раз на самый последний рисунок, на котором DFS закончил свою работу. Видно, что отработав полностью, алгоритм тем не менее не затронул большую часть ребер и, конечно, ни одной петли. Поэтому для того, чтобы заставить его решать нашу задачу и искать эйлеров путь, нам необходимо его модифицировать. На удивление, модификация нужна крайне незначительная.
Связана она будет с тем, что нам необходимо как-то отслеживать посещенные в процессе DFS ребра. Заметим также, что мы можем по нескольку раз проходить через одну и ту же вершину, поэтому в стеке одна вершина может присутствовать несколько раз, если потребуется. По этой же причине нам не нужно теперь как-то помечать уже посещенные вершины, достаточно лишь знать, какая вершина в данный момент является текущей, т.е. той, к которой применяется проверка. Также, чтобы не путаться и не захламлять схему, мы теперь будем не отмечать пройденные ребра, а удалять их. Таким образом, DFS, модифицированный под наши задачи, будет выглядеть примерно так (вершины мы далее будем называть нодами, чтобы не путать с термином «вершина стека»):
1. Заносим стартовую ноду в стек (заметим, что стартовой может быть только нода нечетной степени. Если все ноды четные, начинать можно с любой). Отсюда и далее нода, находящаяся на вершине стека будет считаться текущей.
2. Если у текущей ноды есть исходящие ребра – «переходим» по любому из них на соседнюю ноду. Для этого удаляем пройденное ребро (можно поместить его в отдельный стек) и заносим в стек ноду, на которую мы перешли. Теперь эта нода находится на вершине стека и считается текущей.
3. Повторяем пункт 2, пока текущей не окажется нода без исходящих ребер. Такую ноду мы извлекаем из стека в массив результатов (в отдельный массив результатов можно при этом извлечь ребро).
4. Повторяем пункты 2 и 3, пока не опустошится стек нод (стек ребер опустошится на одну итерацию раньше). Когда стек нод станет пуст, алгоритм завершает свою работу.
Проиллюстрируем его работу.
Вот наш подопытный список слов, он же граф. В нем не имеется эйлерова цикла (есть нечетностепенные ноды), но имеется эйлеров путь (нечетных нод две, А и Ь).
Нам потребуются четыре переменные: стек ребер, стек нод, массив для сохранения эйлерова пути в виде последовательности нод и массив для сохранения решения задачи – правильной последовательности слов. Стартовая нода А, помещаем ее в стек, нода становится текущей:
«Переходим» в ноду Р, ребро удаляем в стек ребер, ноду Р запихиваем в стек, теперь она становится текущей:
Текущая нода имеет два исходящих ребра. Наш DFS храбрый, но наивный, идем вперед:
Далее деваться уже некуда:
Поскольку нода Ь не имеет исходящих ребер, срабатывает граничное условие, по которому она отправляется из вершины стека в массив результатов. Туда же отправляем и ребро. Текущей становится нода К:
У ноды К одно исходящее ребро, переходим в Н:
Далее наш маршрут идет в К через Р и М, вариантов нет:
Текущей нодой становится К, и у нее нет исходящих ребер, впрочем, их вообще не осталось. Граничное условие теперь сработает на каждой вершине, и содержимое стеков перейдет в массивы результатов:
Все, стек пуст, алгоритм закончил работу, реверсируем списки результатов:
{А, Р, К, Р, Н, Р, М, К, Ь} – эйлеров путь.
{Адлер, Рыбинск, Курган, Нарьян-Мар, Рим, Мурманск, Константинополь} – решение задачи.
Несколько слов в заключение
Мне хотелось сопроводить описание алгоритмов пошаговыми иллюстрациями, так как именно их мне не хватало, когда я сам ломал голову над задачей о словах-домино. Из-за этого статья, возможно, получилась слишком длинной. Я не стал приводить конкретную Java-реализацию приведенных алгоритмов, это можно сделать по-разному (можно даже попробовать рекурсию!), оставляю это читателю в качестве упражнения. Для того, чтобы задать направление мысли, рассмотрим три возможных способа представления графа в компьютерной программе.
Первый способ – так называемая матрица смежности (adjacency matrix). Её идея зиждется на том простом факте, что у каждого ребра, как и у каждой палки, два конца.
Посмотрим на рисунок. Мы имеем ориентированный граф с четырьмя узлами, поэтому мы создаем матрицу размером 4х4. Контейнерная природа графа предоставляет нам удивительную свободу относительно того, что именно мы должны хранить в элементах матрицы. Исходя из нашего удобства, мы можем хранить там количество соответствующих связей (как на рисунке), либо в случае, скажем, взвешенного графа мы можем там сохранить вес ребра или список весов, или их сумму. Или же, если захотим – целый объект класса Ребро, полностью описывающий все его свойства. Так или иначе двумерный массив чисел или объектов будет исчерпывающе описывать любой граф, как ориентированный, так и неориентированный.
Второй способ – хранить список ребер (edge list):
И, наконец, третий способ, пожалуй, наиболее наглядный – так называемый список смежности (adjacency list):
Список смежности представляет собой хэшкарту (мапу), ключами которой являются узлы, а значениями – список прилегающих (инцидентных) ребер. Опять-таки, как и в случае с матрицей смежности, тип данных списка ребер мы определяем сами, исходя из собственных нужд. Мы можем занести туда список объектов, содержащих все данные о каждом ребре, а можем, как на рисунке, изображающем ориентированный граф, занести список тех вершин, на которые указывают инцидентные ребра.
У каждого из этих способов есть свои достоинства и недостатки, как по эффективности использования памяти, так и по скорости работы. Я бы рекомендовал взять за основу список смежности, по нему удобно итерироваться, элементами в списках значений хэшкарты будут ребра, то есть сами слова, удаление их и перемещение их в стек будет выглядеть в дебаггере почти так же наглядно, как и цветные схемы в этой статье.
Напоследок - несколько ссылок для тех, кто хочет подробнее изучить предмет, а так же для тех, кто посчитает, что замечательные и простые алгоритмы прохождения графов могут помочь в решении их задач:
Интереснейший обзорный курс по применению алгоритмов теории графов в компьютерных программах (язык английский).Гитхаб Уильяма Фисета, автора курса. Все алгоритмы написаны на Java, их можно запускать из IDEA, создав Gradle-проект.Статья на хабре, в которой приведена рекурсивная реализация алгоритма DFS на Java, Python и C/C++ (язык русский).Огромное количество материалов по алгоритмам графов, в том числе с примерами на Java (язык английский).Психоделическое видео по работе модифицированного DFS на материале иллюстраций, не вошедших в статью (без слов) <-НазадДалее-->
Ну во-первых, очень крутой труд и качество подготовки материала! :) Было крайне любопытно почитать, хотя сам я игру в слова и решал несколько иначе, через ту самую рекурсию и вспомогательный класс Word, на который возлагалась работа по хранению слова, проверке первой последней буквы и совместимости :)
Но от себя добавлю одну штуку. "Суха теория, мой друг, а древо жизни пышно зеленеет" (с)
Когда я учился на JR и в том числе думал о графах, эта штука мне представлялась непонятной вундервафлей, где на картинках вроде как все круто, но вообще не понятно как этим пользоваться.
К чему это я? Совсем без кодовой имплементации материал воспринимать сложнее чем с ней :) Например у того же Седжвика в алгоритмах есть и графические выкладки и куски кода.
А еще читателю может быть любопытно потыкать в дебаггере работающее решение, что бы наглядно посмотреть как именно оно работает :) Само собой, снабженное наглядными примерами.
 Нам потребуются четыре переменные: стек ребер, стек нод, массив для сохранения эйлерова пути в виде последовательности нод и массив для сохранения решения задачи – правильной последовательности слов. Стартовая нода А, помещаем ее в стек, нода становится текущей:
Нам потребуются четыре переменные: стек ребер, стек нод, массив для сохранения эйлерова пути в виде последовательности нод и массив для сохранения решения задачи – правильной последовательности слов. Стартовая нода А, помещаем ее в стек, нода становится текущей:
 «Переходим» в ноду Р, ребро удаляем в стек ребер, ноду Р запихиваем в стек, теперь она становится текущей:
«Переходим» в ноду Р, ребро удаляем в стек ребер, ноду Р запихиваем в стек, теперь она становится текущей:
 Текущая нода имеет два исходящих ребра. Наш DFS храбрый, но наивный, идем вперед:
Текущая нода имеет два исходящих ребра. Наш DFS храбрый, но наивный, идем вперед:
 Далее деваться уже некуда:
Далее деваться уже некуда:
 Поскольку нода Ь не имеет исходящих ребер, срабатывает граничное условие, по которому она отправляется из вершины стека в массив результатов. Туда же отправляем и ребро. Текущей становится нода К:
Поскольку нода Ь не имеет исходящих ребер, срабатывает граничное условие, по которому она отправляется из вершины стека в массив результатов. Туда же отправляем и ребро. Текущей становится нода К:
 У ноды К одно исходящее ребро, переходим в Н:
У ноды К одно исходящее ребро, переходим в Н:
 Далее наш маршрут идет в К через Р и М, вариантов нет:
Далее наш маршрут идет в К через Р и М, вариантов нет:


 Текущей нодой становится К, и у нее нет исходящих ребер, впрочем, их вообще не осталось. Граничное условие теперь сработает на каждой вершине, и содержимое стеков перейдет в массивы результатов:
Текущей нодой становится К, и у нее нет исходящих ребер, впрочем, их вообще не осталось. Граничное условие теперь сработает на каждой вершине, и содержимое стеков перейдет в массивы результатов:






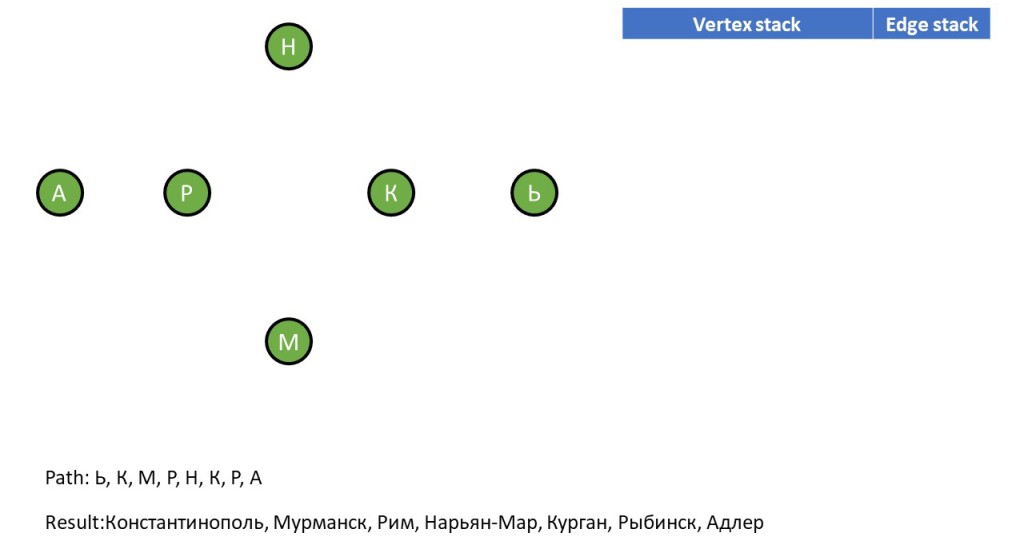 Все, стек пуст, алгоритм закончил работу, реверсируем списки результатов:
{А, Р, К, Р, Н, Р, М, К, Ь} – эйлеров путь.
{Адлер, Рыбинск, Курган, Нарьян-Мар, Рим, Мурманск, Константинополь} – решение задачи.
Несколько слов в заключение
Мне хотелось сопроводить описание алгоритмов пошаговыми иллюстрациями, так как именно их мне не хватало, когда я сам ломал голову над задачей о словах-домино. Из-за этого статья, возможно, получилась слишком длинной. Я не стал приводить конкретную Java-реализацию приведенных алгоритмов, это можно сделать по-разному (можно даже попробовать рекурсию!), оставляю это читателю в качестве упражнения. Для того, чтобы задать направление мысли, рассмотрим три возможных способа представления графа в компьютерной программе.
Первый способ – так называемая матрица смежности (adjacency matrix). Её идея зиждется на том простом факте, что у каждого ребра, как и у каждой палки, два конца.
Все, стек пуст, алгоритм закончил работу, реверсируем списки результатов:
{А, Р, К, Р, Н, Р, М, К, Ь} – эйлеров путь.
{Адлер, Рыбинск, Курган, Нарьян-Мар, Рим, Мурманск, Константинополь} – решение задачи.
Несколько слов в заключение
Мне хотелось сопроводить описание алгоритмов пошаговыми иллюстрациями, так как именно их мне не хватало, когда я сам ломал голову над задачей о словах-домино. Из-за этого статья, возможно, получилась слишком длинной. Я не стал приводить конкретную Java-реализацию приведенных алгоритмов, это можно сделать по-разному (можно даже попробовать рекурсию!), оставляю это читателю в качестве упражнения. Для того, чтобы задать направление мысли, рассмотрим три возможных способа представления графа в компьютерной программе.
Первый способ – так называемая матрица смежности (adjacency matrix). Её идея зиждется на том простом факте, что у каждого ребра, как и у каждой палки, два конца.
 Посмотрим на рисунок. Мы имеем ориентированный граф с четырьмя узлами, поэтому мы создаем матрицу размером 4х4. Контейнерная природа графа предоставляет нам удивительную свободу относительно того, что именно мы должны хранить в элементах матрицы. Исходя из нашего удобства, мы можем хранить там количество соответствующих связей (как на рисунке), либо в случае, скажем, взвешенного графа мы можем там сохранить вес ребра или список весов, или их сумму. Или же, если захотим – целый объект класса Ребро, полностью описывающий все его свойства. Так или иначе двумерный массив чисел или объектов будет исчерпывающе описывать любой граф, как ориентированный, так и неориентированный.
Второй способ – хранить список ребер (edge list):
Посмотрим на рисунок. Мы имеем ориентированный граф с четырьмя узлами, поэтому мы создаем матрицу размером 4х4. Контейнерная природа графа предоставляет нам удивительную свободу относительно того, что именно мы должны хранить в элементах матрицы. Исходя из нашего удобства, мы можем хранить там количество соответствующих связей (как на рисунке), либо в случае, скажем, взвешенного графа мы можем там сохранить вес ребра или список весов, или их сумму. Или же, если захотим – целый объект класса Ребро, полностью описывающий все его свойства. Так или иначе двумерный массив чисел или объектов будет исчерпывающе описывать любой граф, как ориентированный, так и неориентированный.
Второй способ – хранить список ребер (edge list):
 И, наконец, третий способ, пожалуй, наиболее наглядный – так называемый список смежности (adjacency list):
И, наконец, третий способ, пожалуй, наиболее наглядный – так называемый список смежности (adjacency list):
 Список смежности представляет собой хэшкарту (мапу), ключами которой являются узлы, а значениями – список прилегающих (инцидентных) ребер. Опять-таки, как и в случае с матрицей смежности, тип данных списка ребер мы определяем сами, исходя из собственных нужд. Мы можем занести туда список объектов, содержащих все данные о каждом ребре, а можем, как на рисунке, изображающем ориентированный граф, занести список тех вершин, на которые указывают инцидентные ребра.
У каждого из этих способов есть свои достоинства и недостатки, как по эффективности использования памяти, так и по скорости работы. Я бы рекомендовал взять за основу список смежности, по нему удобно итерироваться, элементами в списках значений хэшкарты будут ребра, то есть сами слова, удаление их и перемещение их в стек будет выглядеть в дебаггере почти так же наглядно, как и цветные схемы в этой статье.
Напоследок - несколько ссылок для тех, кто хочет подробнее изучить предмет, а так же для тех, кто посчитает, что замечательные и простые алгоритмы прохождения графов могут помочь в решении их задач:
Интереснейший обзорный курс по применению алгоритмов теории графов в компьютерных программах (язык английский).
Гитхаб Уильяма Фисета, автора курса. Все алгоритмы написаны на Java, их можно запускать из IDEA, создав Gradle-проект.
Статья на хабре, в которой приведена рекурсивная реализация алгоритма DFS на Java, Python и C/C++ (язык русский).
Огромное количество материалов по алгоритмам графов, в том числе с примерами на Java (язык английский).
Психоделическое видео по работе модифицированного DFS на материале иллюстраций, не вошедших в статью (без слов)
<-Назад Далее-->
Список смежности представляет собой хэшкарту (мапу), ключами которой являются узлы, а значениями – список прилегающих (инцидентных) ребер. Опять-таки, как и в случае с матрицей смежности, тип данных списка ребер мы определяем сами, исходя из собственных нужд. Мы можем занести туда список объектов, содержащих все данные о каждом ребре, а можем, как на рисунке, изображающем ориентированный граф, занести список тех вершин, на которые указывают инцидентные ребра.
У каждого из этих способов есть свои достоинства и недостатки, как по эффективности использования памяти, так и по скорости работы. Я бы рекомендовал взять за основу список смежности, по нему удобно итерироваться, элементами в списках значений хэшкарты будут ребра, то есть сами слова, удаление их и перемещение их в стек будет выглядеть в дебаггере почти так же наглядно, как и цветные схемы в этой статье.
Напоследок - несколько ссылок для тех, кто хочет подробнее изучить предмет, а так же для тех, кто посчитает, что замечательные и простые алгоритмы прохождения графов могут помочь в решении их задач:
Интереснейший обзорный курс по применению алгоритмов теории графов в компьютерных программах (язык английский).
Гитхаб Уильяма Фисета, автора курса. Все алгоритмы написаны на Java, их можно запускать из IDEA, создав Gradle-проект.
Статья на хабре, в которой приведена рекурсивная реализация алгоритма DFS на Java, Python и C/C++ (язык русский).
Огромное количество материалов по алгоритмам графов, в том числе с примерами на Java (язык английский).
Психоделическое видео по работе модифицированного DFS на материале иллюстраций, не вошедших в статью (без слов)
<-Назад Далее-->

ПЕРЕЙДИТЕ В ПОЛНУЮ ВЕРСИЮ